jades is a simple, [ja]va written, [d]iscrete [e]vent [s]imulator.
It is inspired by http://www.cs.northwestern.edu/~agupta/_projects/networking/QueueSimulation/mm1.html
dvfs4j permits to control the operating frequency of CPU cores in Linux systems, from within a Java application.
To work, it requires the Linux acpi_cpufreq driver to be enabled. Also, it requires access permissions on the files managed by acpi_cpufreq. This can be achieved, for instance, via:
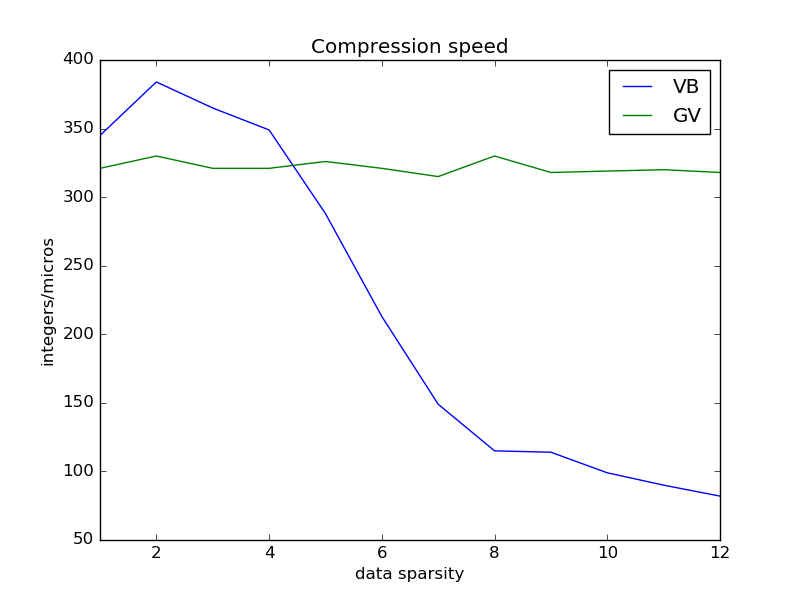
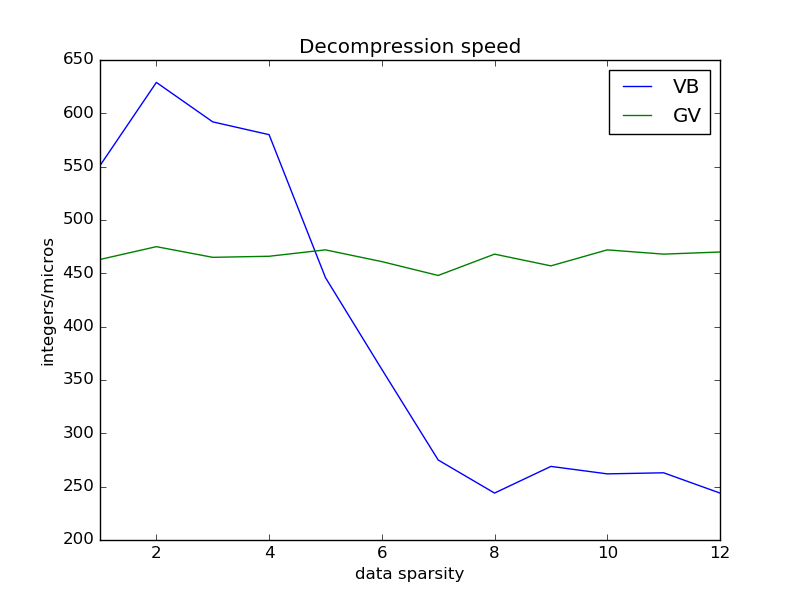
GroupVarint is a technique for compressing arrays of integers. I have written about it here. GroupVarint can be used to compress arrays of monotonically increasing integers. In such case, it is a common practice to compress the gaps between values rather than the original numbers. Gaps are smaller than the original integers, thus they can be compressed using less space. GroupVarint can be efficiently implemented using some bit masking and unaligned memory access [1]. Unluckily, unaligned memory access is not easily achievable in Java. This is why my previous implementation of GroupVarint, instead, used a big switch with 256 entries to decide how to decompress a block of four integers. Such approach is faster than Varint when the original data have low sparsity (i.e., the original numbers are close to each other resulting in small gaps) but it is slower when data are sparse (i.e., we have larger gaps). My conjecture is that this is accountable to branch mis-predictions and cache misses due to the very large switch. Yet, branch mis-prediction is exactly what GroupVarint originally aims to avoid.
For this reason, I have updated my Java implementation of GroupVarint. The new implementation reads integers from the compressed byte array, assuming a little-endian architecture and performing unaligned memory accesses using black magicthe Unsafe class. A bit mask is then applied to the read integer to obtain its original value, as illustrated in [1]. This new implementation is slower than Varint for low data sparsity (maybe because of the overhead introduced by the Unsafe native methods?). However, GroupVarint now maintains its decompression speed constant w.r.t. data sparsity and it is faster than Varint for sparse data (confirming the results in [1]). Below you can see the results of a benchmark performed on an Intel i7-4500U. You can find the code on my github.
Compression speed (in integers per microsecond) for Varint (VB) and GroupVarint (GV)
Deompression speed (in integers per microsecond) for Varint (VB) and GroupVarint (GV)
As a coding exercise, I have implemented in Java a simple version of the Elias-Fano compression schema. This is a technique for compressing arrays of monotonically increasing integers. The interesting aspect is that the Elias-Fano compression schema permits to retrieve the i-th element in the compressed data, without decompressing the whole array. Similarly, it permits to find the index of the first element in the compressed data which is greater or equal to a given value — without decompressing the whole array. You can find the code on my github (here).
Usage
int[] a = ...; //an array of monotonically increasing integers;
//compress the array
EliasFano ef = new EliasFano();
int u = a[a.length - 1]; //the maximum value in a;
int size = ef.getCompressedSize(u, a.length); //the size of the compressed array
byte[] compressed = new byte[size];
ef.compress(a, 0, a.length, compressed, 0);
//decompress the array
int[] b = new int[a.length];
int L = ef.getL(u, a.length); //the number of lower bits (see references)
ef.decompress(compressed, 0, a.length, L, b, 0);
//get the value of the 4-th element in the compressed data
int val = ef.get(compressed, 0, a.length, L, 3);
//get the index of the first element, in the compressed data, greater or equal than 1000
int idx = ef.select(compressed, 0, a.length, L, 1000);
So, I can’t use it to compress non-increasing arrays, isn’t it?
Sure you can! You just need to transform your array into a monotonically increasing one, by adding to the i-th value the sum of the previous values in the array. Then, you can recompute the original i-th element doing i-th minus (i-1)-th value.
EliasFano ef = new EliasFano();
int[] a1 = ...; //a generic array
//make a2 monotonically increasing
int[] a2 = new int[a1.length];
a2[0] = a1[0];
for (int i = 1; i < a1.length; i++) a2[i]=a1[i]+a2[i-1];
//compress a2
int u = a2[a2.length-1]; //the max value in a2
int size = ef.getCompressedSize(u, a2.length);
byte[] compressed = new byte[size];
ef.compress(a2, 0, a2.length, compressed, 0);
//get the original i-th value of a1, as i-th minus (i-1)-th of a2
int L = ef.getL(u, a2.length);
int val = ef.get(compressed, 0, a2.length, L, i)-ef.get(compressed, 0, a2.length, L, i-1);
Dependecies
– JUnit 4
References
For a general understanding of the Elias-Fano technique, see:
Sebastiano Vigna, “The Revenge of Elias and Fano” (here)
More advanced material:
Sebastiano Vigna, “Quasi-succinct indices”, WSDM’13
Giuseppe Ottaviano and Rossano Venturini, “Partitioned Elias-Fano indexes”, SIGIR’14
Integer compression can improve performance in various applications. For instance, search engines’ inverted indices can benefits from compression. These data structures, in fact, are mainly composed by integer numbers and need to be kept in RAM. Integer compression can help to reduce their size and to maintain more of the structure in main memory.
Varint (also called Variable Byte o VInt) is a byte-aligned, variable-length, encoding technique to compress integer numbers. It uses the lower 7 bits of a byte to store the number value, and the higher bit to signal if another byte is needed (when 7 bits are not enough). When the higher bit is set to 1, we need to read another byte to get the number value. If it is set to 0, we are done decoding the number.
Examples:
1 is 00000001
15 is 00001111
511 is 11111111 00000011
131071 is 11111111 11111111 00000111
[1, 15, 511, 131071] is 00000001 00001111 11111111 00000011 11111111 11111111 00000111
While it is simple and effective, Varint needs up to four if-then-else’s to decode an integer. This can limit its decoding speed. Now, consider the fact that the possible higher bits configurations can be represented with 2 bits (00: one byte is needed, 01: two, 10: three, 11: four). We can pack four 2 bits configurations in a single byte and encode four integers in the variable-length format. At decode time, we just need to read the first byte to decompress four numbers at once!
This techinque is called Group Varint. More about this can be found in:
1) Jeff Dean (Google), “Challenges in Building Large-Scale Information Retrieval Systems”, WSDM’09
As programming exercise, I implemented Group Varint in Java. You can find the groupvarint code on github.
Usage example:
int a[] = {1, 2, 3 , 4, 5, 6, 7, 8};
byte b[] = new byte[GroupVarint.getSafeCompressedLength(a.length)];
int c[] = new int[a.length];
GroupVarint.compress(a, 0, a.length, b, 0);
GroupVarint.uncompress(b, 0, c, 0, a.length);
with negative numbers:
int a[] = {0, 1, 2, -1, -2, Integer.MAX_VALUE, Integer.MIN_VALUE};
byte b[] = new byte[GroupVarint.getSafeCompressedLength(a.length)];
int c[] = new int[a.length];
int support[] = Arrays.copyOf(a, a.length);
ZigZagGroupVarint.compress(support, 0, support.length, b, 0);
ZigZagGroupVarint.uncompress(b, 0, c, 0, a.length);
PHPCrawl is a webcrawler/webspider-library written in PHP. It supports filters, limiters, cookie-handling, robots.txt-handling, multiprocessing and much more.
Unluckily, there isn’t a way to limit PHPCrawl crawl depth. Here I propose a patch for its current version (0.82), that adds two methods to the PHPCrawler class: getMaxDepth and setMaxDepth.
The usage is intuitive:
$crawler = new PHPCrawler();
$crawler->setURL($startingURL);
$crawler->setMaxDepth($n);
$crawler->go();
The crawler will get pages from level 0 (the $startingURL) to level $n – 1.
By default, the crawling depth limit is set to PHPCrawler::UNLIMITED_CRAWLING_DEPTH = 0. This means that the crawler will get any web page, regardless of its depth from the starting URL.
UPDATE: In the comments section, Hiruka suggested that this patch it is not easily applicable using NetBeans patch facility. I recommend using the patch command from the command line, or some other tool. For instance, Hiruka succeeded to apply the patch using git.
UPDATE 2 (28/07/2014): I have uploaded a patch revision. This should fix the small bug reported by Sylvain LAVIELLE in the comment section (‘undefined offset’).
UPDATE 3 (28/08/2014): some more bug fixes. Also, I introduced an (experimental) feature to set the HTTP Accept-Language Header
// set preferred language
$crawler->setAcceptLanguage("it, en;q=0.8");
At work, we were recently trying to estimate performance differences in keeping some big data structures (> 8Gb) in main memory or in disk memory. Surprisingly, our experiments (run on Linux machines) showed very little discrepancies between the two scenarios, while in-memory experiments were supposed to be much faster than on-disk ones.
A blog post from Changing Bits gave me an hint on what was going on. The “culprit” of this anti-intuitive behavior was the disk caching done by Linux. Due to this caching mechanism, the data structure kept on disk was also in the system cache. Then, accessing to it resulted in reads from the main memory instead than in I/O to the disk.
It is viable, however, to open a file in a way which performs I/O directly on the disk, instead than on the system cache. This is possible using the O_DIRECT flag while opening the file. Nevertheless, this flag it is not supported by Java.
A workaround to this limitation might be to modify the JVM, or to write JNI code. A simpler approach is to use the super cool JNA library. “JNA provides Java programs easy access to native shared libraries without writing anything but Java code – no JNI or native code is required”.
Attached to this post you can find my implementations for InputStream and OutputStream using JNA and the O_DIRECT flag. Please note that these classes are meant to be used under a Linux system with glibc version >= 2.15. To adapt these to aother environments, please look at JNA documentation.
I’ve made some experiments (I’m not going to say it was a proper benchmarking), comparing standard java InputStream/OutputStream, JNAInputStream/JNAOutputStream using and not using direct I/O. I’ve write and red a series of 10000 integers one hundred times, and taken the average time for input and output operations. JNA streams using O_DIRECT are far slower than standard Java’s, while JNA streams with the flag turned off can be even faster. This means that the difference in running time is not due the overhead of using an external library such as JNA. The experimental class is attached as well.
In conclusion, Linux disk caching is really an amazing feature. On an idling machine, it can cache data structure even bigger than 8 GB, drammatically improving software performances. Nevertheless, it can be useful to turn off this feature if required during benchmarking activities.
During December 2012, the student Daniele Orlando organized an hackathon at my university. The contest topic was about the social networking divide. For various reasons, I couldn’t attend it.
My idea would have been about creating an hub for my study course. We currently have (at least) three information channels: the offical site, the facebook group, and the super-cool google group. It can be pretty chaotic to follow, or update, all of these.
My idea for the contest was to create a single point of access to these channels, leveraging technologies like RSS and facebook api. I’ve lately implemented this idea. It’s been quite easy, it took me probably less than a day to develop the proof-of-concept you’ll find attached to this post.You can also find a running demo here.
My social hub uses SimplePie to access RSS contents (which is the case of the website and of the google group) and facebook social graph api to access facebook (open) groups. Also, with my social hub you can republish contents via RSS.
Since I suck at web designs, I’ve just used a Srinivas Tamada’s template.
To run my code on your machine you’ll just need a LAMP installation and a facebook application key and secret. A facebook app is needed only if you want to read from a facebook open group. Make sure to ask for user_groups privilege while creating the facebook app.
Be aware!! This is just a proof of concept release!!
I’ve developed this application with my friend and colleague Giacomo Lamonaco for the exam of Ottimizzazione Combinatoria 2.
The aim of this software is to extract from a tweet collection the terms that better represent its content.
We’ve tackled the problem modelling it as a set covering problem, thus looking in a tweet collection for the smallest set of terms able to cover the entire collection.
Modeling & implementation
The problem has been modeled with the classical set covering formulation:
Where xi is the i-th dictionary term, the dictionary is the set of all the terms found in the tweet collection, the tweet is a generic collection tweet and the collection is the set of all the tweet downloaded from Twitter via its API.
We’ve written a Java application using Twitter4J. Our application downloads a set of about 1500 tweets from Twitter. The collection is downloaded searching for a query, selected from the “Trending topics”. The limit of 1500 tweets is imposed by the API limitation.
Once downloaded the collection, this is indexed using our Java classes. Every tweet is analysed this way:
Tokens that represent http links, #hashtags*, @mentions are removed. Remove also tokens that are ‘stopwords’ (words so much used that have little semantic weight)
The remaining tokens are stemmed. As result, we have the terms.
If the term is shorter than 3 characters, it’s removed. Otherwise save it in the index (which represents the dictionary). Save it also in a term list associated to the ID of the corresponding tweet (every list represents a tweet, the set of all the lists represents the collection).
This process guarantees us to work only with meaningful terms, removing those with little semantic relevance.
Please note that part of this process is language specific (stopword list, stemmer, …). Our application is set for tweet collections written in English.
Once the collection is indexed, the data structures at point 5 are passed as parameters to our set cover solver. The solver has been written using libraries for integer linear programming. The solver implements the described model, returning as result a cover represented by a set of term.The solver has been implemented in two versions. One uses GLPK’s JNI via JavaILP, another one directly uses CPLEX’s JNI.
The benefit in using JavaILP it’s the possibility of switching among JNIs maintaining a single interface. For example, one can use GLPK or lp_solve without modifying the algorithms. Using CPLEX directly, instead, the benefits is in having far better solving performances.
* #hashtags are removed because usually they are already present in the query you use to download the collection. Moreover they may lead to a cover that contains just them.
Usage
Usually I launch the application inside Eclipse, so I’ll refer to that environment.
Create a new run configuration using MainILP as main class.
In VM arguments type: -Djava.library.path=/path/to/your/jni
where /path/to/your/jni is where there are your JNIs for GLPK, lp_solve, CPLEX, etc. (not provided with this software; for GLPK start looking here).
Then you can fill the Program arguments depending on what you’re doing:
Download a tweet collection:
-d path/to/the/collection query
The program will download from twitter to path/to/the/collection a tweet collection related to the query. Ex.: -d /home/matteo/Downloads/columbine.xml Columbine
Cover a tweet collection:
-c path/to/the/collection
The program will find a term cover for the tweet collection at path/to/the/collection. Ex.: -c /home/matteo/Downloads/columbine.xml
Cover a tweet collection excluding some terms:
-ec path/to/the/collection word_to_exclude
The program won’t index word_to_exclude and then will find a term cover. Ex.: -ec /home/matteo/Downloads/columbine.xml Colorado
Shortly after the the dramatic shooting at the Batman premier, I’ve downloaded a collection for the term ‘Columbine’. Covering that collection, this is the result:
–SOLUTION– Number of element in the cover: 15.0 columbin, freq: 895 shoot, freq: 298 colorado, freq: 262 peopl, freq: 86 movi, freq: 80 crazi, freq: 45 sad, freq: 27 read, freq: 23 dark, freq: 17 noth, freq: 10 prai, freq: 7 deep, freq: 1 turnonoth, freq: 1 justic, freq: 1 edit, freq: 1
—MOST VALUABLE TWEETS— [226359371112792064]First the Columbine shooting and now at the movies. That’s so sad. People are so sick. My heart goes out to those in Colorado. [226359731848085505]im never going to colorado they had columbine and now niggas shooting people in movie theatres [226358442917511168]apparently colorado is filled with fucked up people who like to shoot other people for no reason. columbine and now the movie shootings. smh [226357986409476096]Colorado is the weirdest state in the union. The people there are cracked. The Ramseys, Columbine, and a guy who shoots babies at the movies [226357081932984321]Remind me to never move to Colorado. Jonbenet Ramsey, columbine high school, the dark knight rises shooting. Crazy people in the Midwest.
This site may use cookies. By continuing to use the site, you agree to the use of cookies. more information
By the "EU Cookie Law", we have to inform you that this website may use cookies in order to function. If you continue to use this website without changing your own cookie settings, or if you click "Accept" below, then you are consenting to this.